Le FAT5 : Flash Attention T5

Alors que beaucoup d’efforts ont été consacrés à l’optimisation de transformer de type décodeur, abandonnant ainsi l’encodeur,
nous pensons qu’il est essentiel de maintenir une architecture encodeur-décodeur.
En effet, cette architecture qui présente des performances intéressantes pour l’instruction tuning
Au-delà du NLP sur lequel nous nous concentrons dans cet article de blog, l’architecture encodeur-décodeur est très utilisée dans d’autres domaines
comme l’audio ou les séries temporelles par exemple. L'encodeur d'une telle architecture est également utilisé dans des modèles de diffusion.
Dans cette logique, nous avons décidé de nous concentrer sur le T5
Dans cet article, sont détaillons les optimisations que nous avons mises en place afin de pré-entraîner de manière efficiente un T5 de 147M de paramètres en français en un temps raisonnable (1 461 H pour 419Mds de tokens) et avec des moyens limités (1 unique A100 ; soit un budget de calcul d'environ 1 900 euros).
Pour ce faire, nous avons conçu des noyaux CUDA/Triton afin de rendre la Flash Attention compatible avec T5 et de fournir une inférence linéaire, étendant ainsi la taille du contexte qui peut être prise en compte par le modèle.
Le code de pré-entrainement est disponible sur notre répertoire GitHub sous licence Apache-2.0. et les poids sur notre compte Hugging Face.
Nous avons donc choisi de travailler avec un T5 et en pratique avec le nanoT5
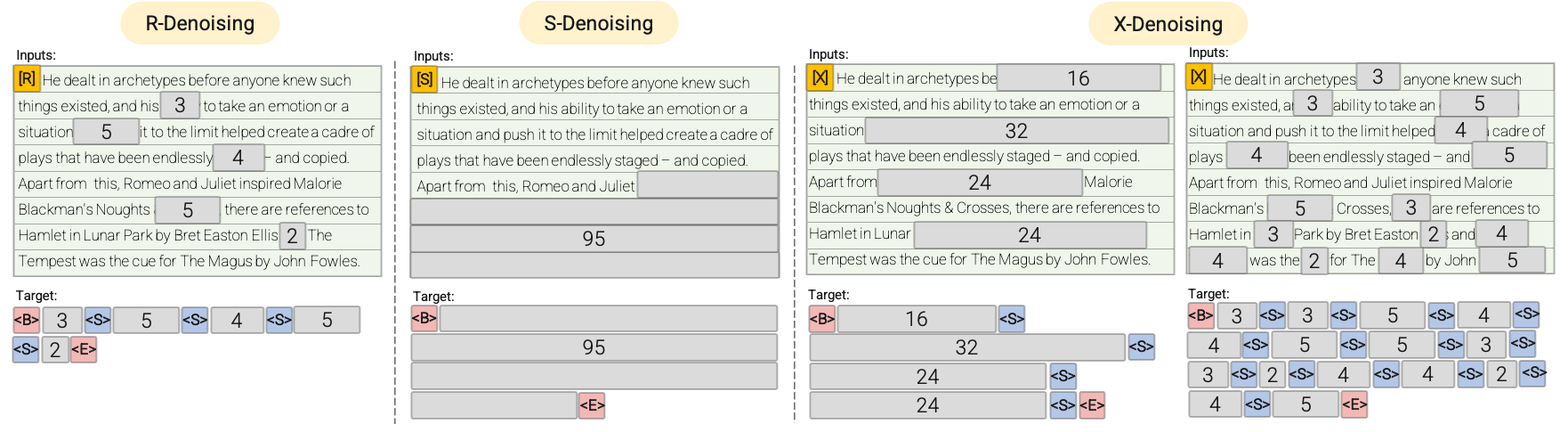
Pour les tâches de prétexte lors du pré-entraînement, nous avons suivi celles d'UL2
denoiser_list=[
{"mu": 3.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[R]"},
{"mu": 8.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[R]"},
{"mu": 4.0, "r": 0.0, "max_spans": 1, "prefix": "[S]"},
{"mu": 3.0, "r": 0.5, "max_spans": max_token_length, "prefix": "[X]"},
{"mu": 8.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[X]"},
{"mu": 64.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[X]"},
{"mu": 64.0, "r": 0.5, "max_spans": max_token_length, "prefix": "[X]"}]
denoiser_proportions=[0.165, 0.165, 0.34, 0.0825, 0.0825, 0.0825, 0.0825]
avec mu la taille du n-gram, r le pourcentage de masquage dans le n-gram et prefix le type de tâche de prétexte.
La signification des lettres [R], [S] et [X] est décrite ici
et nous vous invitons à consulter notamment l'image explicative ici.
Pour avoir un entraînement rapide, nous nous sommes orientés sur la Flash Attention
Notre travail a abouti au pré-entraînement d'un T5 en français de 147M de paramètres : le FAT5 small.
Le jeu de données que nous avons utilisé est composé de la partie en français du corpus CulturaX
Ce modèle a été évalué sur cinq tâches : le résumé de textes, la classification binaire, le question answering, la reconnaissance d’entités nommées et la sentence similarity.
Ne disposant que de deux A100 (une de 80Go et une de 40Go), nous avons dû consacrer un peu de temps afin d’implémenter des optimisations permettant d'exploiter au mieux notre matériel.
En effet, avant même d’entraîner un modèle voire de modifier son architecture, il faut s’assurer qu’on optimise l'usage des capacités de calcul de nos GPU.
Plusieurs facteurs peuvent expliquer un entraînement sous-optimal d’un modèle de deep learning :
• Le manque de nourriture (disk-bounded - limitation en disque)
• La bande passante mémoire (memory-bounded - limitation en bande passante mémoire)
• La vitesse de calcul (compute-bounded - limitation en calcul)
Idéalement, on aimerait que le modèle soit limité par la vitesse de calcul, c’est-à-dire que le GPU soit utilisé à pleine capacité.
Partant de ce constat, nous avons travaillé sur trois points principaux :
• L’optimisation du disque du GPU
• L’optimisation de la bande passante de la mémoire du GPU
• L’optimisation de l’utilisation des Tensor Cores
Il s’agit donc de points à la fois hardware mais aussi software.
Dans la suite de cette section, tout ce que nous avons réalisé/implémenté pour apporter une réponse aux limites rencontrées est disponible dans un encadré en vert. Des notes/commentaires sont trouvables dans un encadré en bleu.
La limitation en disque intervient soit lors du chargement des données, soit lors des opérations de prétraitement.
Dans les deux cas, cela se matérialise par un problème de lenteur.
Si la limitation vient des accès disques, plusieurs solutions sont possibles :
Mettre les données en RAM
Cela résout le problème de manière radicale mais suppose que la base de données rentre en RAM, ce qui est loin d’être évident du fait de sa petite taille.
Ce n’est donc pas la solution que nous avons retenue.
Mettre les données sur un disque plus rapide et/ou moins utilisé
Si vous avez un accès physique à votre serveur de GPU, il est très utile d’intégrer des NVMe dans la configuration de celui-ci.
Il faut aussi faire attention à ne pas avoir trop de processus de différents entraînements qui tirent sur un même disque. Il est alors préférable d’avoir plusieurs petits disques plutôt qu’un gros.
Un effet indirect bénéfique est qu’une telle configuration coûte moins cher 😉
.parquet sont plus efficients que les .csv.
On peut aussi utiliser des formats spécifiquement développés dans ce but comme le .beton de ffcv Nous utilisons la bibliothèque Datasets Arrow.
De plus, si les données chargées depuis le Hub d’Hugging Face ont été ajoutées avec la fonction push_to_hub(),
alors le jeu de données est par défaut converti au format parquet.
Nous invitions le lecteur à consulter le code
suivant qui
illustre la façon dont nous procédons dans notre tutoriel sur le FAT5 appliqué au jeu de données Minipile
Si la limitation vient du traitement des données après leur chargement :
Il est possible d’utiliser plusieurs processus pour traiter les données en parallèle
Par exemple, le paramètre num_workers du Dataloader de PyTorch
Vous pouvez retrouver dans notre code les valeurs que nous utilisons pour ce paramètre pour notre FAT5 small.
Le goulot d’étranglement peut aussi venir du DataCollator
C'est notamment le cas lorsqu’il y a des tâches complexes à effectuer (masquage d’image ou débruiteurs multiples sur des tâches de NLP).
On pourra alors construire un DataCollator personnalisé pour la tâche.
On appliquera les méthodes traditionnelles pour optimiser la vitesse de celui-ci.
De même, l’emploi de la vectorisation de Numpy permettra de traiter plus rapidement des listes qu'avec des boucles for.
D’une manière générale, Numpy est plus rapide que PyTorch pour ce type de tâches.
On pourra aussi utiliser des méthodes de compilation comme numba
Nous avons suivi ce principe et développé un DataCollator personnalisé pour notre FAT5 dont vous pouvez consulter le code ici.
Il gère les tâches de prétexte UL2 tout en ayant un mécanisme de batch dynamique pour réduire le padding (plus d'informations dans la section suivante).
Comme il n’y avait pas d’implémentation du DataCollator d’UL2 disponible en PyTorch jusqu’ici, nous espérons que cela pourra être utile à d’autres travaux.
Réaliser un padding efficace
Lorsque l’on travaille avec des séquences, on a naturellement tendance à padder un ensemble de séquences pour pouvoir construire des batchs.
Les tokens de padding engendrent alors des calculs inutiles.
La première chose à faire est de limiter le padding à la séquence de taille maximum et non à une valeur maximale.
C’est la technique du padding dynamique.
Avec cette technique, il peut néanmoins rester des tokens de padding. Pour les gérer, il existe deux possibilités :
• soit utiliser une méthode de groupage des données avec des tailles similaires
(par exemple, ce paramètre
dans la bibliothèque Transformers
• soit concaténer différents exemples dans un DataCollator personnalisé.
Nous avons opté pour la seconde option et nous renvoyons donc le lecteur à nouveau au code de notre DataCollator de mélange de débruiteurs (UL2).
Des heuristiques plus optimisées doivent probablement être mises en place.
Nous avons fait un test en proposant une
fonction
dans le DataCollator afin de trier les input_ids et les labels par longueur décroissante.
Néanmoins ceci est plutôt long pour un gain d'empaquetage minime.
Un travail plus conséquent serait à effectuer sur ce point.
La limitation en bande passante mémoire est plus difficile à traiter. Une opération limitée par la mémoire est une opération dont le temps global d’exécution est restreint par les accès mémoires. C’est notamment le cas pour les LLMs particulièrement au niveau de l’inférence. Le diagnostic peut être posé à partir du profiler de PyTorch :

Une autre possibilité pour établir un diagnostic est d’utiliser un simple nvidia-smi :
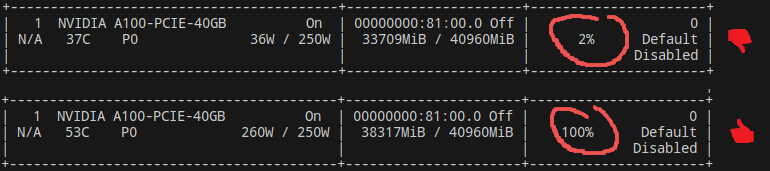
Utile pour savoir si un problème est présent mais donne peu d’information sur la nature de ce problème. C’est pourquoi nous avons une préférence pour le profiler.
La technique reine pour optimiser la bande passante de la mémoire du GPU est de développer un kernel CUDA fusionnant dans la SRAM plusieurs opérations limitantes. Cela peut limiter la copie de larges matrices dans l’HBM pour les recharger immédiatement ensuite dans la SRAM. C’est désormais une caractéristique courante des transformers décodeurs grâce à la Flash Attention.
Comme la Flash Attention ne gère pas les biais attentionnels (additifs) du T5, nous l’avons étendue en développant un noyau CUDA personnalisé. Comme évoqué dans l’introduction, c’est en réalité successivement deux versions successives de ce noyau que nous avons implémentées. Sans pour autant entrer dans les détails des 650 lignes de code de l’implémentation de la première version (consultable ici), l’idée générale et simplifiée (pour une passe avant) est la suivante :
Alors que la première version du noyau est générique, la seconde (disponible ici) est spécifique au fonctionnement de modèles avec encodage positionnel relatif (ce qui est le cas du T5). L’idée générale et simplifiée (pour une passe avant) est la suivante :
De cette façon, alors que la première version la matrice de biais B nécessitait une mémoire quadratique, ici nous nous ramenons
à une mémoire linéaire permettant d'effectuer des inférences sur des dizaines de milliers de tokens.
Pour la conception de cette seconde version, nous nous sommes inspirés du noyau Triton du TurboT5 que nous avons porté en CUDA et étendu au full bf16.
Notons que les deux versions développées peuvent être utilisées avec plusieurs encodages positionnels.
Nous invitions le lecteur à consulter ce fichier
contenant des classes compatibles avec la Flash Attention pour le
RelativePositionalEncoding
Au moment de la rédaction de ces lignes,
les deux pull request (une pour chaque version du noyau, disponibles ici
et ici) ouvertes sur le répertoire officiel de la Flash Attention n’ont pas été mergées.
Le lecteur devra donc provisoirement recompiler nos patchs personnalisés de la Flash Attention pour pouvoir utiliser nos modèles.
Nous invitons le lecteur à consulter la partie Benchmark plus bas dans l'article pour visualiser l'amélioration apportée par ces deux noyaux.
Bien que nous n’y ayons pas eu recours, il est à noter que certaines libraires contiennent des implémentations d’opérateurs courant fusionnés, par exemple Apex
Triton
Une implémentation en Triton de la
Flash Attention 2 gérant les biais d’attention
est fournie pour ceux qui ne souhaitent pas recompiler un patch personnalisé pour la Flash Attention.
Pour cela, nous nous sommes appuyés sur le répertoire de FlagAttention
En complément de cette implémentation (dont l'usage est facultatif), d’autres parties de l’architecture ont été optimisées à l’aide de noyaux Triton ad hoc, à savoir :
• la perte d’entropie croisée (et la perte z
• la couche de RMSNorm
Nous nous sommes notamment inspirés de Unsloth
Nous invitons le lecteur se référer à la partie Benchmark plus bas dans l'article pour visualiser l'impact de cette optimisation.
torch.compileUne approche plus simple est de compiler les modèles avec torch.compile.
PyTorch se charge alors de faire les fusions possibles, éventuellement en réordonnant des opérations.
Il s’agit alors de faire la chasse aux cassures dans le graphe de compilation qui sont des retours à un mode d’exécution « eager » impactant
négativement la performance de l’opération.
Voir la documentation officielle pour plus de détails.
Une autre possibilité consiste à un usage conjoint d’un noyau kernel personnalisé et de torch.compile.
L'implémentation de cette option est grandement simplifiée depuis la
version 2.4 de PyTorch.
Nous invitons le lecteur à se référer à la partie benchmark disponible plus bas dans l’article afin de mesurer les performances mémoire des différentes techniques décrites.
Les GPU récents possèdent des unités dédiées aux opérations tensorielles : les TensorCore. Les utiliser correctement est essentiel.
A nouveau, pour établir un diagnostic, il est conseillé de se référer au profiler de PyTorch qui indique la proportion de TensorCore utilisé pour chaque noyau CUDA :

Concernant les optimisations réalisables :
La première consiste à employer des tailles de tenseurs de certains multiples de 8 ou de 64. Nous invitons le lecteur à se référer à la documentation de Nvidia, en particulier cet article et cet article pour déterminer le multiple à sélectionner en fonction de la précision désirée.
Dans cette logique, nous avons entraîné un tokenizer de taille 32 768 (8**5), suivant cette observation de KARPATHY.
Il s'agit d'un BPE
Le lecteur pourra trouver le code utilisé ici.
Changer d’optimiseur par rapport à l’implémentation initiale du modèle peut être judicieux pour accélérer la convergence du modèle
(cela peut néanmoins empêcher la reproduction des résultats du papier original).
Les optimiseurs accélèrent la convergence en permettant des tailles de batchs conséquentes comme dans le cas de LAMB
Des versions plus efficaces des optimiseurs peuvent être aussi utilisées comme l’option fused
dans l’optimiseur Adam de PyTorch
ou encore les optimiseurs disponibles dans Apex.
Nous avons utilisé l’optimiseur l’optimiseur original du T5, AdamWScale.
Pour les valeurs des hyperparamètres, nous utilisons lr = 5e-3, betas = (0.9, 0.999), eps = 1e-6 et weight_decay = 0.0
en nous basant sur les observations de Wilson WONGSO.
En effet, il s'avère que tous les optimiseurs alternatifs testés ne convergeaient pas.
Nous avons fait en sorte que notre version d'AdamWScale dispose du paramètre foreach.
bf16Les GPU récents permettent d’exploiter pleinement l’utilisation de précision réduite
(permettant de gagner un facteur 2 de débit par rapport au fp32).
Le bf16 n’est disponible que sur les architectures Ampere ou plus récentes mais autorise de s’affranchir de méthode
de loss scaling fp16
grâce à une plage dynamique plus grande (l’exposant est codé sur 8 bits comme le fp32).
Dans cette logique, nous entraînons nos modèles en bf16.
Plus précisément, alors qu'au début de nos expérimentations nous utilisions du bf16-mixed, nous avons recouru à
la sommation compensée de Kahan
afin de pouvoir utiliser du full bf16 dans notre optimiseur.
A nouveau, le code de notre optimiseur est consultable ici.
Certaines techniques existent pour limiter l’utilisation de mémoire GPU par le modèle tel que le
gradient checkpointing
ou les méthodes type ZeRO
L’utilisation de plusieurs GPUs est délicate. Réalisée naïvement, elle peut résulter en des performances inférieures à l’implémentation sur un seul GPU gâchant alors des ressources de calculs. C’est le cas notamment lorsque des goulets d’étranglement se forment au niveau des communications entre les GPU. Il s’agit d’être sûr que le modèle n’est pas limité par la bande passante entre les cartes ou de s'assurer que les cartes sont connectées avec des bandes passantes suffisantes via des techniques type NVLink par exemple.
A noter aussi que les techniques d’optimisation requièrent en général de synchroniser tous les GPU à la fin d’un batch. De ce fait, si un GPU est plus lent que les autres (ou est utilisé par un autre processus), le modèle est bridé à la vitesse du GPU le plus lent de l’ensemble.
Ayant pré-entraîné notre modèle sur une seule A100 80Go, nous n'avons pas pu expérimenter le parallélisme.
Nous nous sommes penchés sur les éléments listés ci-dessus dans une optique d’optimiser le pré-entraînement de notre modèle.
En pratique, nous devons ensuite le finetuner pour le spécialiser sur les tâches finales qui nous intéresse.
Pour cela, nous recourrons à des têtes. Pour le T5 « standard »,
cinq sont disponibles dans Transformers permettant d’effectuer toutes les tâches faisables :
T5ForConditionalGeneration,
T5ForSequenceClassification,
T5ForTokenClassification,
T5ForQuestionAnswering
et T5EncoderModel.
Là encore, un travail d’optimisation peut être effectué.
Pour la génération conditionnelle, le principal point est de s’assurer d’avoir un processus de génération efficace.
Pour les têtes portant sur des tâches de classification (séquence, NER et QA), il faut s’assurer que l’on utilise la partie encodeur
du T5 puisque le décodeur n’est pas essentiel pour celles-ci comme le montre l’EncT5
La dernière tête sert simplement à ne garder que la partie encodeur d'un modèle encodeur-décodeur. Elle n'a donc pas besoin d'être optimisée.
Concernant la tête ForConditionalGeneration, notre
implémentation
repose sur le processus de génération disponible dans le
nanoT5
car est 14% plus rapide que l’implémentation d’Hugging Face.
Concernant les têtes de classification, l’implémentation est disponible dans ce
fichier.
Il s'agit d'un fichier disjoint du fichier modeling car nos implémentations diffèrent de celles disponibles dans Transformers.
En effet, les implémentations des têtes T5ForSequenceClassification et de T5ForQuestionAnswering disponibles dans Transformers reposent
sur l’encodeur et le décodeur du T5 ce qui est donc inefficient.
Nous avons donc recodé ces deux têtes pour n'utiliser que l'encodeur.
Nous avons alors suivi la même structure que la tête T5ForTokenClassification disponible dans Transformers qui,
utilise aussi que l'encodeur et donc reprenons telle quelle.
Le nombre de TFLOPS (trillions de calculs en virgule flottante qu'un processeur peut effectuer en une seconde) est probablement la mesure la plus parlante
pour étayer l'impact des optimisations effectuées.
Nous comparons alors quatre approches :
• l'implémentation SPDA (Scaled Dot Product Attention) avec full bias,
• la même implémentation mais en Triton,
• l'implémentation en Flash Attention RPE, c'est-à-dire le second noyau que nous avons développé (peut être vu comme le turboT5 mais en C++/Cuda avec bf16 full),
• l'implémentation en Flash Attention i.e. sans biais. Nous l'indiquons pour avoir une référence car elle est inutilisable en pratique pour un T5.
Pour la passe avant, nous avons :

Pour la passe avant, nous pouvons observer que l'approche en Triton permet 1,34 fois plus de FLOPS que celle en SPDA et que l'approche en Flash Attention RPE permet 1,99 fois plus de FLOPS que celle en SPDA.
Nous pouvons aussi constater que notre implémentation en bf16 est équivalente à du fp16 (faisant même mieux en taille 512).
C'est suite à ce benchmark que nous avons décidé d'entraîner notre modèle en français en bf16, head_dim = 128 et avec une séquence 1024.
Pour la passe arrière, nous avons :

Pour la passe arrière, l'implémentation en Triton se révèle moins efficace que SPDA avec 0,71 fois les FLOPS de SPDA. Celle en Flash Attention RPE est plus ou moins équivalente à SPDA (1,018 fois plus de FLOPS).
Nous pouvons également observer que Triton en head_dim 64 est plus efficace que Triton en head_dim 128.
Nous indiquions plus haut avoir optimisé des parties de l’architecture à l’aide de noyaux Triton ad hoc, à savoir l'entropie croisée et la couche de RMSNorm.
Les benchmarks suivants doivent en illustrer la raison.
Pour l'entropie croisée, nous obtenons une passe avant 7 à 11,4 fois plus rapide, une passe arrière 3,26 à 3,75 plus rapide ainsi qu'une mémoire réduite d'un facteur 4 :

Pour la couche de RMSNorm, nous obtenons une passe avant 3 à 5 fois plus rapide, une passe arrière 2,33 à 4,33 plus rapide ainsi qu'une mémoire réduite d'un facteur 3,2 :

Notez que l'ensemble des graphiques des benchmarks peuvent être générés automatiquement via le code suivant.
Nous avons appliqué notre travail au français en pré-entraînant un modèle de 147M de paramètres.
Le jeu de données que nous avons utilisé est un mélange de CulturaX, Wikipedia, justice_fr et The Stack.
Notre tokenizer de taille 32 768 (8**5) est entraîné sur CulturaX et The Stack.
Notre modèle est pré-entraîné sur une séquence de 1 024 tokens.
Nous souhaitions comparer les performances de notre modèle face à d'autres modèles en français précédemment publiés comme le CamemBERT
Pour cela, il nous est paru important de faire des comparaisons à nombre de tokens vus équivalent.
Nous avons ainsi essayé d'estimer le nombre de tokens vus par ces deux modèles via la formule nombre de steps × la taille de la séquence × la taille du batch. Nous n'avons pas trouvé les informations dans la publication du BARThez pour le faire. Pour le CamemBERT nous l'estimons à environ 419,4 Mds de tokens au maximum. Ce chiffre pourrait être en réalité moins élevé car nous ne connaissons pas le nombre de tokens de padding vus par ce modèle (là où dans notre cas, nous n'en utilisons pas). Ainsi, nous avons pré-entraîné notre modèle sur le nombre maximal de tokens vus par le CamemBERT.
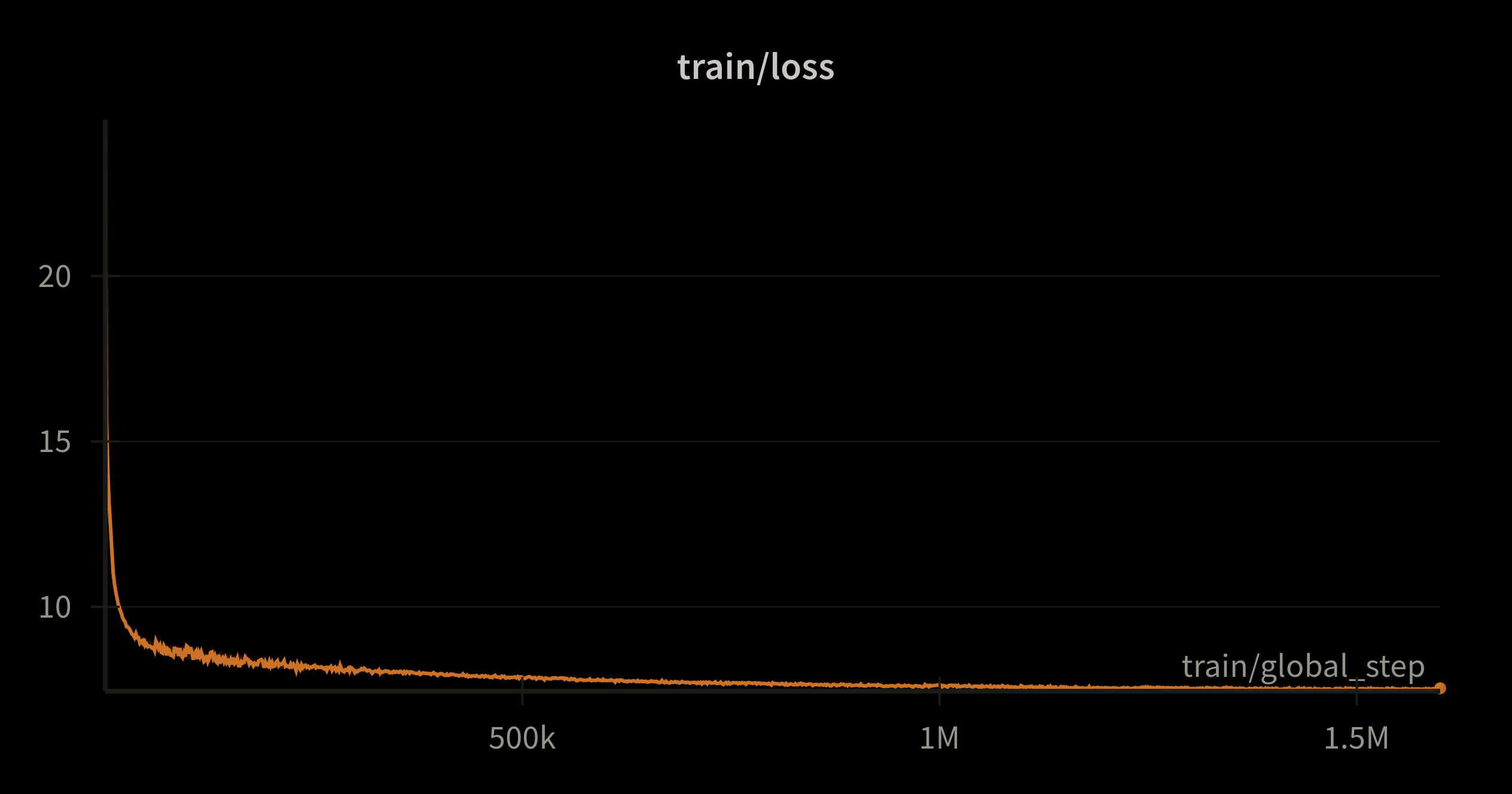
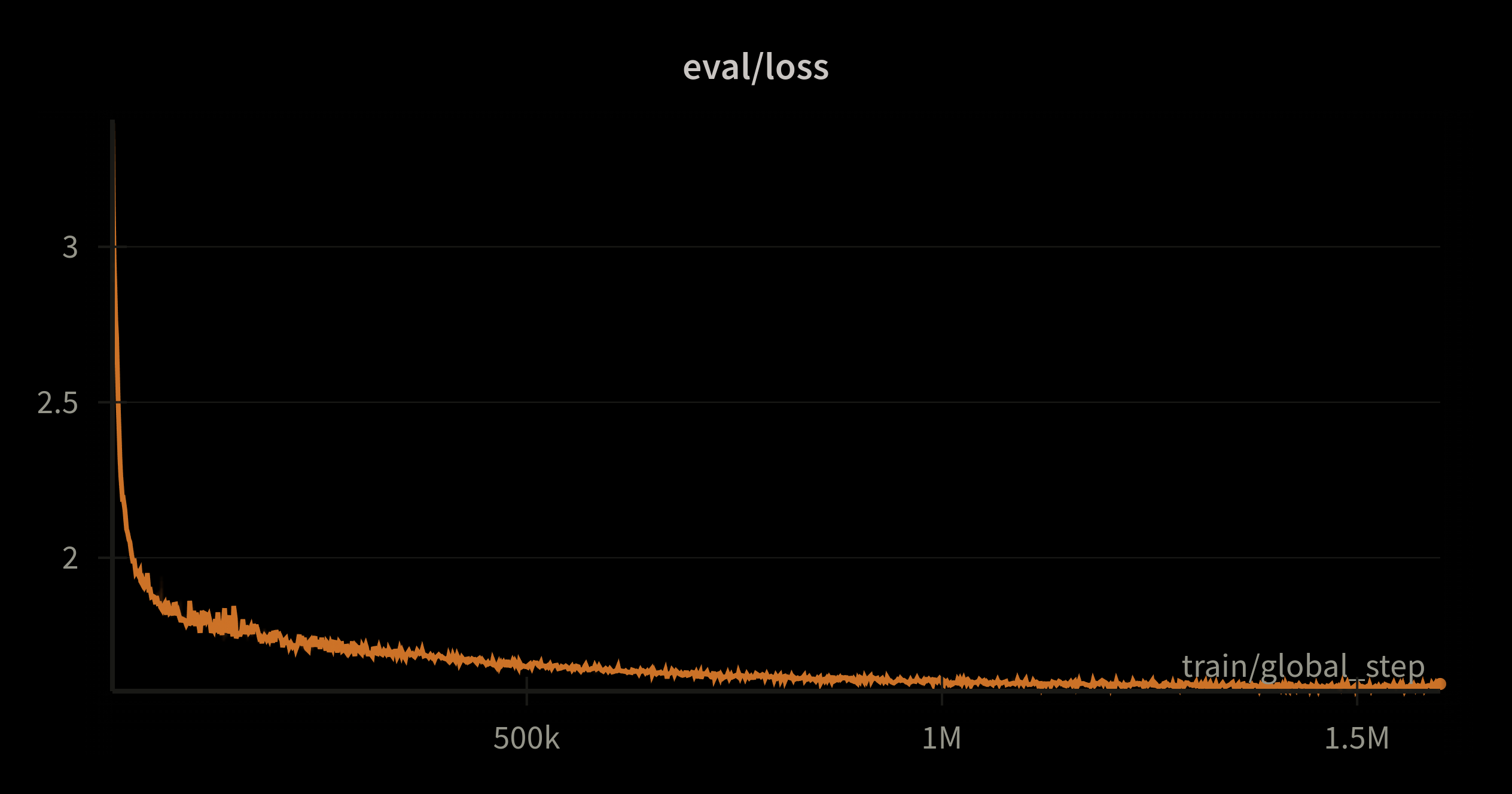
Nous nous sommes également intéressés à comparer notre modèle face à lui-même, c'est-à-dire que nous avons évalué ses performances sur les tâches en aval toutes les 100 000 steps (~26 Mds de tokens) au cours du pré-entraînement.
Dans le tableau ci-dessous, nous avons listés le nombre de tokens équivalents à chaque intervalle de 100 000 steps.
| Modèle | Nombre de tokens ✝ |
|---|---|
| FAT5-small-100K | 26 214 400 000 (100 000 × 1024 × 256) |
| FAT5-small-200K | 52 428 800 000 (200 000 × 1024 × 256) |
| FAT5-small-300K | 78 643 200 000 (300 000 × 1024 × 256) |
| FAT5-small-400K | 104 857 600 000 (400 000 × 1024 × 256) |
| FAT5-small-500K | 131 072 000 000 (500 000 × 1024 × 256) |
| FAT5-small-600K | 157 286 400 000 (600 000 × 1024 × 256) |
| FAT5-small-700K | 183 500 800 000 (700 000 × 1024 × 256) |
| FAT5-small-800K | 209 715 200 000 (800 000 × 1024 × 256) |
| FAT5-small-900K | 235 929 600 000 (900 000 × 1024 × 256) |
| FAT5-small-1000K | 262 144 000 000 (1 000 000 × 1024 × 256) |
| FAT5-small-1100K | 288 358 400 000 (1 100 000× 1024 × 256) |
| FAT5-small-1200K | 314 572 800 000 (1 200 000 × 1024 × 256) |
| FAT5-small-1300K | 340 787 200 000 (1 300 000 × 1024 × 256) |
| FAT5-small-1400K | 367 001 600 000 (1 400 000 × 1024 × 256) |
| FAT5-small-1500K | 393 216 000 000 (1 500 000 × 1024 × 256) |
| FAT5-small-1600K | 419 430 400 000 (1 600 000 × 1024 × 256) |
| camembert (base ou large) | 419 430 400 000 (100 000 × 512 × 8192) |
✝ équivaut au nombre de steps × la taille de la séquence × la taille du batch
Nous nous sommes focalisés sur cinq tâches :
• Du résumé de textes pour illustrer un usage de la tête T5ForConditionalGeneration,
• De la classification binaire pour illustrer un usage de la tête T5ForSequenceClassification,
• De la reconnaissance d’entités nommées pour illustrer un usage de la tête T5ForTokenClassification,
• Du question answering pour illustrer un usage de la tête T5ForQuestionAnswering.
• De la sentence similarity pour illustrer un usage de la tête T5EncoderModel.
Les tâches de classification nous semblent être importantes à évaluer car elles sont généralement ignorées par les benchmarks des grands modèles de langue génératifs alors qu’il de tâches fréquemment utilisées en pratique par les entreprises (recherche documentaire, classification pour d'avis clients, anonymisation de données, etc.).
En témoigne sûrement le fait que 6 ans et demi après sa sortie, BERT
Dans les tableaux suivants, nous soulignons pour le FAT5 la ligne obtenant le meilleur résultat pour chacune des tâches. Nous interprétons les résultats de la partie génération après le tableau sur le résumé de texte. Les résultats sur la partie classification sont interprétés après l'ensemble des tableaux de classification binaire, QA, NER et de sentence-similarity.
Pour cette tâche, nous avons utilisé le jeu de données orange_sum
| Modèle | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| FAT5-small-100K (147M) | 28,17 | 10,60 | 20,62 |
| FAT5-small-200K (147M) | 28,72 | 10,86 | 20,68 |
| FAT5-small-300K (147M) | 28,76 | 10,85 | 20,63 |
| FAT5-small-400K (147M) | 28,59 | 10,76 | 20,60 |
| FAT5-small-500K (147M) | 28,98 | 10,97 | 20,72 |
| FAT5-small-600K (147M) | 29,04 | 11,20 | 20,89 |
| FAT5-small-700K (147M) | 28,72 | 10,87 | 20,77 |
| FAT5-small-800K (147M) | 29,00 | 10,91 | 20,78 |
| FAT5-small-900K (147M) | 29,30 | 11,34 | 21,22 |
| FAT5-small-1000K (147M) | 29,10 | 11,21 | 21,08 |
| FAT5-small-1100K (147M) | 29,43 | 11,40 | 21,15 |
| FAT5-small-1200K (147M) | 29,30 | 11,38 | 21,18 |
| FAT5-small-1300K (147M) | 29,38 | 11,38 | 21,18 |
| FAT5-small-1400K (147M) | 29,29 | 11,18 | 21,14 |
| FAT5-small-1500K (147M) | 29,48 | 11,48 | 21,22 |
| FAT5-small-1600K (147M) | 29,30 | 11,27 | 21,10 |
| Barthez |
31.44 | 12.77 | 22.23 |
| mBarthez (458M) | 32.67 | 13.73 | 23.18 |
Nous pouvons constater que notre modèle performe moins bien que le Barthez. Nous pouvons émettre quelques hypothèses à ce sujet.
Premièrement, il est vraisemblable que notre processus de génération de texte ne soit pas optimal. Ne connaissant pas celui utilisé par le Barthez, nous avons simplement recouru aux paramètres par défaut de la fonction generate de Hugging Face pour ne pas avantager notre modèle avec un processus de génération qui serait plus sophistiqué.
Deuxièmement, nous n'avons pas utilisé de prompt pour conditionner la génération, ce qui aurait pu bénéficier à notre modèle puisque le T5 est le modèle ayant introduit ce système.
Troisièmement, le Barthez a sûrement vu plus de tokens que notre modèle. Bien que nous n'arrivons pas à déterminer ce nombre d'après la publication des auteurs, il est indiqué que c'est un modèle BART
Nous utilisons une version nettoyée du jeu de données allocine
| Modèle | Accuracy |
|---|---|
| FAT5-small-100K (67,4M) | 96,05 |
| FAT5-small-200K (67,4M) | 96,20 |
| FAT5-small-300K (67,4M) | 96,48 |
| FAT5-small-400K (67,4M) | 96,60 |
| FAT5-small-500K (67,4M) | 96,60 |
| FAT5-small-600K (67,4M) | 96,60 |
| FAT5-small-700K (67,4M) | 96,68 |
| FAT5-small-800K (67,4M) | 96,59 |
| FAT5-small-900K (67,4M) | 96,75 |
| FAT5-small-1000K (67,4M) | 96,62 |
| FAT5-small-1100K (67,4M) | 96,69 |
| FAT5-small-1200K (67,4M) | 96,71 |
| FAT5-small-1300K (67,4M) | 96,69 |
| FAT5-small-1400K (67,4M) | 96,65 |
| FAT5-small-1500K (67,4M) | 96,57 |
| FAT5-small-1600K (67,4M) | 96,69 |
| distilcamembert (68,1M) | 96,74 |
| camembert-base (111M) | 97,27 |
| camembert-large (337M) | 97,15 |
Note : dans le tableau et dans les suivants, distilcamembert se réfère au distilcamembert-base
Pour cette tâche, nous avons utilisé frenchNER dans sa configuration 4 entités (PER, LOC, ORG, MISC)
| Modèle | F1 PER | F1 LOC | F1 ORG | F1 MISC |
|---|---|---|---|---|
| FAT5-small-100K (67,1M) | 96,51 | 94,48 | 87,24 | 75,81 |
| FAT5-small-200K (67,1M) | 96,90 | 94,83 | 88,78 | 76,82 |
| FAT5-small-300K (67,1M) | 97,25 | 95,11 | 88,86 | 77,48 |
| FAT5-small-400K (67,1M) | 97,18 | 95,08 | 89,11 | 77,42 |
| FAT5-small-500K (67,1M) | 97,25 | 95,16 | 89,16 | 76,91 |
| FAT5-small-600K (67,1M) | 97,19 | 95,19 | 88,85 | 76,88 |
| FAT5-small-700K (67,1M) | 97,17 | 95,14 | 89,39 | 76,82 |
| FAT5-small-800K (67,1M) | 97,34 | 95,20 | 89,18 | 77,27 |
| FAT5-small-900K (67,1M) | 97,19 | 95,21 | 89,04 | 76,83 |
| FAT5-small-1000K (67,1M) | 97,31 | 95,26 | 89,24 | 76,84 |
| FAT5-small-1100K (67,1M) | 97,11 | 94,99 | 88,52 | 76,30 |
| FAT5-small-1200K (67,1M) | 97,19 | 95,11 | 88,79 | 76,86 |
| FAT5-small-1300K (67,1M) | 97,15 | 95,00 | 88,62 | 76,58 |
| FAT5-small-1400K (67,1M) | 97,22 | 95,09 | 89,01 | 77,00 |
| FAT5-small-1500K (67,1M) | 97,32 | 95,34 | 89,39 | 77,30 |
| FAT5-small-1600K (67,1M) | 97,14 | 95,22 | 89,24 | 76,88 |
| distilcamembert (67,5M) | 97,26 | 95,24 | 89,10 | 79,88 |
| camembert-base (110M) | 97,80 | 95,78 | 90,27 | 81,38 |
| camembert-large (336M) | 98,17 | 96,37 | 91,87 | 83,35 |
Nous avons voulu finetuner notre modèle sur cette tâche mais nous nous sommes rendu compte que notre tokenizer a deux problèmes.
Premièrement, nous avons oublié d'ajouter le token de début de phrase.
Deuxièmement, nous avons décidé d'utiliser un fast BPE tokenizer. Nous avons appris après coup que l'argument `add_special_tokens=True` ne fonctionne pas avec ce type de tokenizer.
Corriger ces deux points nécessite de post-traiter les encodages du tokenizer avant d'effectuer notre tâche de finetuning ce qui n'est pas élégant et nécessite du temps que nous n'avons pas dans l'immédiat.
Nous invitons le lecteur à prendre les résultats de cette section avec des pincettes.
Nous avons effectué un finetuning sur cette tâche afin de vérifier que la tête T5EncoderModel fonctionnait
mais nous ne nous focalisons pas sur les résultats obtenus car nous nous interrogeons sur la qualité du benchmark sur lequel nous évaluons les modèles,
à savoir MTEB FR
En effet, Nils Reimers, créateur du MTEB, a récemment remis en cause dans un tweet
la pertinence de ce benchmark, le déclarant « mort ».
Plus tôt dans l'année, nous avions d'ailleurs observé des fuites de données et des duplications dans ce benchmark
(voir ici et
ici).
Alexey Vatolin a ensuite étendu ces observations en prenant également en compte les lignes vides (voir ici).
Dans le tableau ci-dessous, nous finetunons sur une version nettoyée du jeu de données stsb_multi_mt
| Modèle | Moyenne | Classification | Clustering | PairClassification | Reranking | Retrieval | STS | Summary |
|---|---|---|---|---|---|---|---|---|
| FAT5-small-400K (67,1M) | 52,2 | 59,8 | 39,1 | 77,5 | 56,1 | 29,1 | 74 | 29,8 |
| distilcamembert (68,1M) | 51,3 | 60,7 | 37,4 | 77 | 51,1 | 25,2 | 76,4 | 31,3 |
Nous observons dans le graphique de la convergence de la masked accuracy, que les performances de la partie encodeur du modèle progressent dans un premier temps avant de s'aplatir.
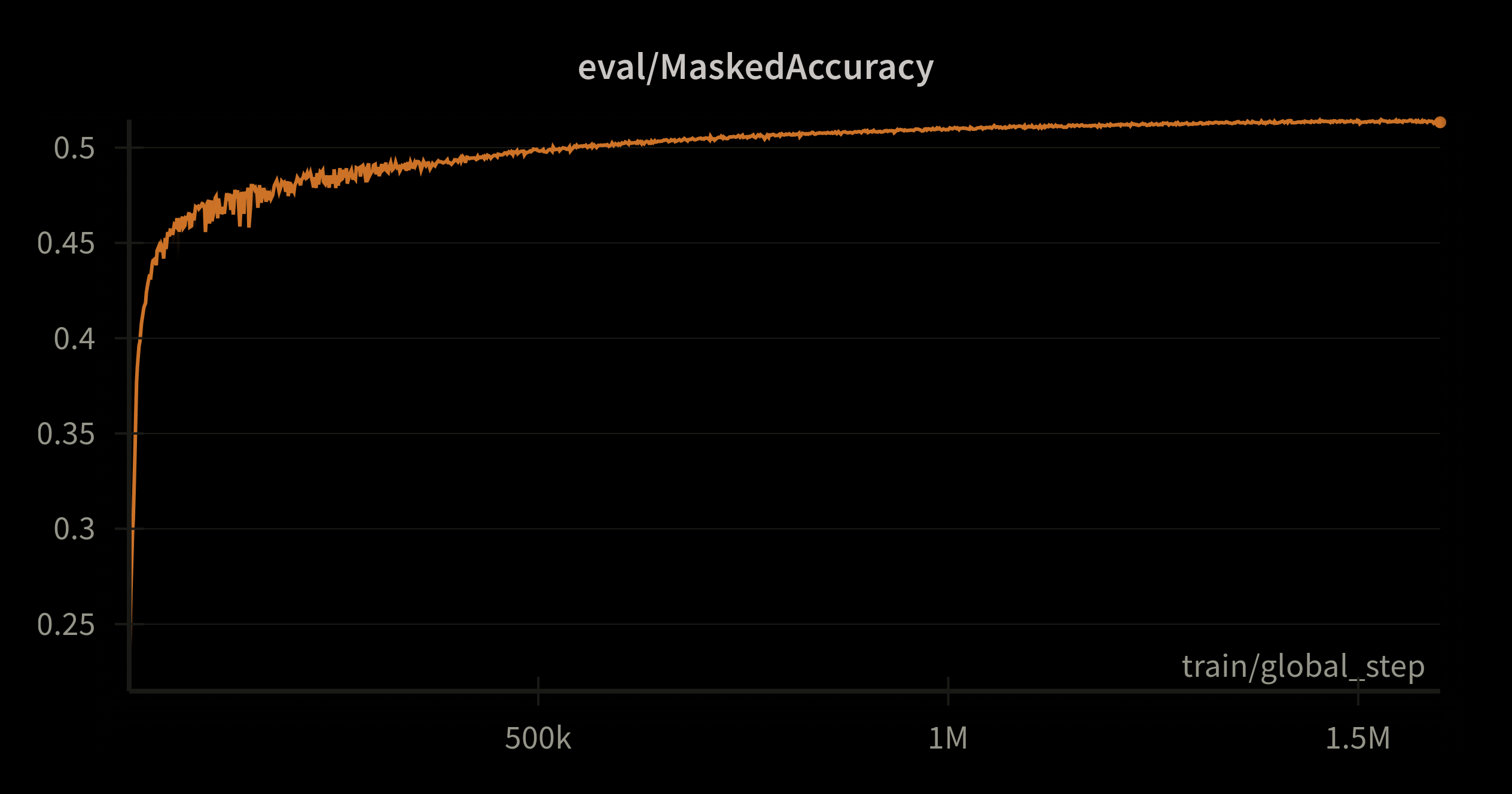
Ce phénomène s'observe aussi dans les résultats des finetunings, le FAT5 match les performances du distilcamembert aux alentours de 800 ou 900K steps (à l'exception de l'entité MISC pour la NER) mais ne fait pas mieux au-delà. Cela est néanmoins encourageant en vue d'un passage à l'échelle puisque les modèles distillés issus de modèles plus importants donnent habituellement de meilleurs résultats que les modèles entraînés de zéro.
Notons que cette forme de plateau dans les performances serait à confirmer en effectuant plusieurs exécutions avec des configurations différentes (au niveau de la seed notamment) pour proposer des résultats sous la forme d'un intervalle au lieu d'un résultat unique (pour chaque step évaluée, nous utilisons une seed de 42).
Signalons également que ce plafonnement pour la partie encodeur a déjà été observé par d'autres auteurs. On peut par exemple citer le CamemBERT(a) 2.0
Une dernière observation pouvant être faite, est que si les performances plafonnent, il est possible de se permettre de stopper le pré-entraînement plus tôt et donc réduire les coûts.
Dans le tableau ci-dessous, nous listons des estimations de coûts (en euros) pour le pré-entraînement de notre modèle selon divers cloud providers.
Pour chacun d'eux, nous nous basons sur le prix horaire d'une A 100 80GB proposé le 20 décembre 2024.
Nous indiquons deux cas, un pré-entraînement sur 262 Mds de tokens (seuil où on observe que les performances sur les tâches de classifications commencent à plafonner et que les gains marginaux deviennent alors faibles) sur 419 Mds de tokens (le nombre de tokens vus au maximum par le CamemBERT).
| Cloud provider | Prix horaire d'une A 100 | Prix pour 262 Mds de tokens | Prix pour 419 Mds de tokens | Note |
|---|---|---|---|---|
| Sesterce | 1,29 | 1 182 | 1 891 | |
| AWS | 1,77 | 1 616 | 2 586 | |
| OVH | 2,75 | 2 475 | 3 960 | En optant pour un payement mensuel plutôt qu'horaire, le prix dans les deux cas n'est plus que de 2 200€. |
| Azure | 3,31 | 3 021 | 4 833 | Le prix horaire a été calculé à partir du prix mensuel de 8 A100. |
| Google Cloud | 3,52 | 3 214 | 5 143 |
Les émissions carbones ont été estimées à l’aide du Machine Learning Impact calculator
Notre modèle a été pré-entraîné sur une A100 PCIe 80GB, sur une infrastructure privée.
Pour l'efficacité carbone, nous nous sommes basés sur les chiffres journaliers indiqués
par electricitymaps pour la France lors de la période de notre pré-entraînement.
Les finetunings ont été effectués pour leur part sur une A100 PCIe 40GB.
Le temps d’exécution se comptant généralement en heures voire en minutes, pour l’efficacité carbone nous nous référons alors au chiffre d’electricitymaps indiqué pour l’heure en question plutôt que pour le chiffre journalier.
Nous estimons ainsi les émissions de notre modèle à 14,084 kg eq. CO2,
dont 13,5 kg eq. CO2 pour le pré-entraînement et 0,584 kg eq. CO2 pour les 49 finetunings.
À ce chiffre, nous devons ajouter des émissions supplémentaires estimées à 6,24 kg eq. CO2.
Elles correspondent au finetuning de modèles pour établir les baselines auxquelles se comparer (0,475 kg eq. CO2), à nos travaux préliminaires en bf16 mixed (4,735 kg eq. CO2 pour le pré-entraînement de trois modèles différents sur 300K steps) et à des tests en bf16 full avant l'entraînement de notre modèle final (1,03 kg eq. en pré-entraînement d'un modèle deux fois plus petit sur 400K steps).
Ainsi, au total, nous estimons l’empreinte carbone de nos travaux à 20,324 kg eq. CO2.
Sur la phase de pré-entraînement (nous n’avons pas assez d’informations pour faire des estimations pour les autres phases), il est alors possible de nous situer vis-à-vis des autres modèles en français pré-entraînés listés précédemment :
| Modèle | Temps (H) | Emissions (kg Co2 eq) | Note |
|---|---|---|---|
| Camembert | 6 144 | 106,91 ✝ | 24H × 256 Tesla V100-SXM2-32GB à 58g (moyenne sur 2019) Les auteurs ne précisent pas les chiffres pour la version large |
| Flaubert base |
13 120 | 190,24 à 228,29 ✝ | 410H × 32 V100 à 58g (moyenne sur 2019) Le type de la V100 n’est pas spécifié (V100-SXM2-32GB ? V100-SXM2-16GB ? V100-PCIE-16GB ?) |
| Flaubert large |
49 920 | 723,84 à 868,61 ✝ | 390H × 128 V100 à 58g (moyenne sur 2019) Le type de la V100 n’est pas spécifié (V100-SXM2-32GB ? V100-SXM2-16GB ? V100-PCIE-16GB ?) |
| Barthez | 7 680 ★ | 107,52 à 129,02 ✝ | 60H × 128 V100 à 56g (moyenne sur 2020) Le type de la V100 n’est pas spécifié (V100-SXM2-32GB ? V100-SXM2-16GB ? V100-PCIE-16GB ?) |
| FAT5-small | 1 461 | 13,5 | 1 461H × 1 A100 à 36,96 g (moyenne entre le 18/10/2024 et le 19/12/2024) |
✝ les chiffres indiqués sont des estimations à partir des informations fournies par les auteurs dans leur publication
★ nous indiquons uniquement les heures pour le pré-entraînement en français appliqué par dessus le pré-entraînement en anglais initial sur lequel se base le modèle
Notre contribution se focalise sur le français avec l'introduction d'un nouveau modèle. Pour d'autres langues, nous ne pouvons pas nous permettre d’effectuer un travail de la même envergure.
Néanmoins, nous mettons à disposition un code permettant d'adapter vers notre méthode des poids de (m)T5/FLAN-T5
Notez cependant que cette adaptation est limitée puisque le pré-entraînement supplémentaire devra être effectué dans la précision du modèle original. Par exemple, si les poids du modèle sont en fp32 (ce qui est le cas du FLAN-T5), l'entraînement ne sera pas aussi rapide que le FAT5 qui est en bf16.
Pour les anglophones, nous avons déjà adapté les poids des différentes versions du FLAN-T5 à notre méthode. Tous les poids peuvent être trouvés dans cette
collection Hugging Face.
Si vous souhaitez pré-entraîner votre propre modèle (pour être spécialisé dans un domaine spécifique par exemple, et ainsi bénéficier d'un tokenizer personnalisé), nous vous renvoyons à nouveau vers le tutoriel indiquant comment procéder pour pré-entraîner un modèle sur minipile. Notez que nous avons testé et entraîné le modèle du tutoriel sur une A100, cela peut ou non fonctionner avec d'autres GPU.
Terminons cet article en évoquant ce que nous comptons, ou du moins aimerions, donner comme suite à ce travail.
Il s'agit ici de choses qui auraient déjà dû être présentes dans cet article mais qui ont pris plus de temps que prévu.
Typiquement, nous avons terminé la conception des jeux de données mais n'avons pas eu le temps d'effectuer les finetunings.
L'objectif est d'effectuer ces tâches prochainement pour pouvoir ajouter les résultats obtenus dans une actualisation de cet article de blog.
Le FAT5 actuel est utilisable. Néanmoins, du fait des problèmes avec le tokenizer entraînant des post-traîtement inélégant pour certaines tâches, nous n'excluons pas de ré-entraîner un modèle (sur 1M de steps seulement) avec un nouveau tokenizer permettant un usage plus simple du modèle.
Nous souhaiterions tester les capacités de génération de textes du FAT5 de façon plus optimale via notamment l'usage de prompts en développant un modèle instruct.
Pour cela, nous disposons du DFP (Dataset of French Prompts)
Au-delà du NLP, nous possédons aussi plus de 2M de lignes de prompt de type "open QA" qui doivent nous permettre de tester le FAT5 sur des tâches/connaissances plus généralistes.
La conception de ce modèle instruct doit en outre nous permettre de travailler sur son alignement, notamment via un jeu de données de 12M de lignes pour effectuer de la DPO en français.
Le pré-entraînement effectué porte sur des séquences de 1 024 tokens. Or, le noyau CUDA que nous avons développé prend en compte des encodages positionnels permettant d'étendre fortement cette taille de contexte ainsi qu'une inférence linéaire.
Dans cette logique, nous avons créé deux jeux de données de longues séquences en français (un de QA, un de résumé de textes) sur lesquels nous souhaitons finetuner notre modèle.
Les éléments listés ci-dessous portent sur des pistes à plus long terme. C'est-à-dire que leur implémentation prendra du temps et feront l'objet d'un nouvel article de blog le cas échéant.
Bien que déjà satisfaits par les optimisations effectuées sur la mémoire via notre noyau CUDA, nous pensons que nous pouvons pousser ces résultats plus loin via d'autres techniques. Par exemple, nous pouvons citer la méthode CCE (Cut Cross-Entropy)
De plus, alors que nous nous sommes concentrés sur le pré-entraînement, un travail serait à faire sur l'inférence qui en pratique consomme le plus de ressources dans le temps une fois le modèle en production. Nous pensons notamment à utiliser la SageAttention2
Dans ce travail, nous présentons un modèle à mémoire linéaire.
Une amélioration supplémentaire consisterait à ce qu’en plus de cette mémoire, le modèle opère avec des calculs linéaires.
L’idée est de substituer l’attention quadratique traditionnelle par une autre forme d’attention.
On peut penser à certaines déjà appliquées au T5, comme celle du LongT5
LoLCATs
Des T5/FLAN-T5 ont été entraînés jusqu'à 11 milliards de paramètres, montrant ainsi que cette architecture peut passer à l'échelle.
Nous aimerions ainsi proposer des modèles de taille plus importante avec un FAT5-base et un FAT5-large de respectivement 305M et 973M de paramètres que nous souhaiterions ensuite distiller. L'objectif est de proposer des modèles consommant le moins possible en routine/inférence.
Nous nous attendons également à ce que les modèles distillés donnent de meilleures performances que des modèles de taille équivalente entraînés de zéro.
Cela doit nous permettre également de proposer des modèles qui seront utilisés en pratique. En effet, en l'état actuel pour le français, si l'utilisateur est davantage motivé par les performances plutôt que par la taille mémoire du modèle, il a davantage intérêt à utiliser un CamemBERTa 2.0 pour les tâches de classification. Le présent FAT5 doit ainsi davantage être vue comme une preuve de concept avant un passage à l'échelle qui doit le rendre compétitif.
Dans le cadre de ce travail, nous avons utilisé des données en français « générique » principalement issues de CulturaX. Pendant l'entraînement de notre modèle,
Hugging Face a introduit le jeu de données FineWeb2
Au-delà du français générique, nous souhaitons surtout pouvoir appliquer notre méthodologie à des domaines spécifiques (médecine, variante régionale du français, etc.).
Pour cela, il faudrait entraîner un nouveau tokenizer dédié et effectuer un nouveau pré-entraînement pour chacun des domaines choisis.
L’intérêt des optimisations mises en place et présentées dans cet article de blog est de permettre une réduction importante du coût du pré-entraînement.
Nous souhaiterions ensuite mener une comparaison entre ces petits modèles spécialisés vs. de grands modèles génériques.
La dernière piste que nous souhaiterions explorer est une actualisation de l'architecture du T5. En effet, les encodeurs-décodeurs ayant été délaissés, ils n'ont pas bénéficié des améliorations qu'ont reçues ces derniers mois les modèles décodeurs (couches d'activation ou de normalisation plus récentes, multi token prediction
Nous avons introduit le modèle FAT5 (Flash Attention T5) en détaillant notre démarche d’optimisation de différents éléments des processus de pré-entraînement et de finetuning.
Celui-ci se base sur des noyaux permettant d'utiliser la Flash Attention avec un T5 et de donner une mémoire linéaire au modèle.
Nous avons notamment appliqué nos travaux au français en guise de preuve de concept et fait en sorte qu’il soit aussi utilisable dans n'importe quelle autre langue.
Nous espérons que notre méthode, permettant de pré-entraîner de zéro un modèle de 147M de paramètres pour un coût limité, pourra être utile aux personnes disposant de ressources de calculs limitées.
Elle ouvre également une voie vers un retour à un usage de modèles encodeur-décodeur plutôt qu’uniquement décodeur.
@misc {FAT5,
title = { FAT5: Flash Attention T5 },
author = { Boris ALBAR and Loïck BOURDOIS },
organization = { Centre Aquitain des Technologies de l'Information et Electroniques },
year = 2025,
url = { https://huggingface.co/spaces/CATIE-AQ/FAT5-report },
doi = { 10.57967/hf/4160 },
publisher = { Hugging Face }
}
{kind=link}